超文本传输协议 (HTTP)
简介
HTTP 是一种应用层协议,用于访问万维网资源。术语 hypertext 表示包含指向其他资源链接的文本,以及读者可以轻松理解的文本。
HTTP 通信由客户端和服务器组成,客户端向服务器请求资源。服务器处理请求并返回请求的资源。HTTP 通信的默认端口是端口 80 ,但可以根据 Web 服务器配置更改为任何其他端口。当我们使用互联网访问不同网站时,会使用相同的请求。我们输入一个 Fully Qualified Domain Name ( FQDN )作为 Uniform Resource Locator ( URL )来访问所需的网站
URL
通过 URL 访问 HTTP 资源,它提供了比仅仅指定我们想要访问的网站更多的规范。让我们看看 URL 的结构:
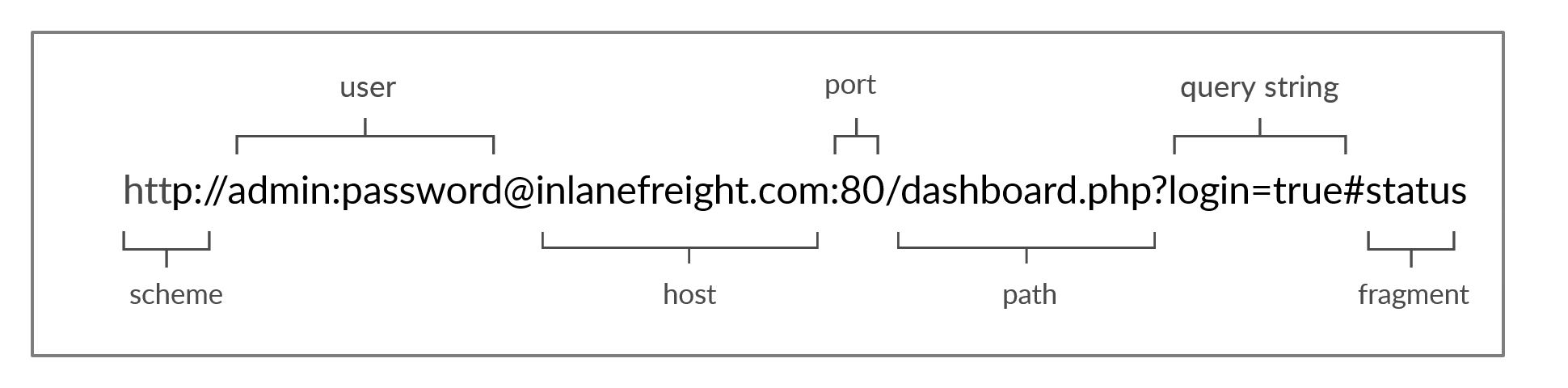
含义:
| 组件 | 示例 | 描述 |
|---|---|---|
| Scheme | http://https:// | 这用于识别客户端正在访问的协议,并以一个冒号和两个斜杠( :// )结束 |
| User Info | admin:password@ | 这是一个可选组件,包含用于向主机进行身份验证的凭据(由冒号 : 分隔),并且与主机通过一个 at 符号( @ )分隔。 |
| Host | inlanefreight.com | 主机表示资源的位置。这可以是一个主机名或一个 IP 地址。 |
| Port | :80 | Port 与 Host 由冒号( : )分隔。如果没有指定端口, http 方案默认使用端口 80 ,而 https 默认使用端口 443 。 |
| Path | /dashboard.php | 这指向被访问的资源,可以是文件或文件夹。如果没有指定路径,服务器将返回默认的索引(例如 index.html )。 |
| Query String | ?login=true | 查询字符串以问号( ? )开头,由参数(例如 login )和值(例如 true )组成。多个参数可以通过与号( & )分隔。 |
| Fragments | #status | 片段由浏览器在客户端处理,以定位主要资源中的部分(例如页面的标题或部分)。 |
| 访问资源并非需要所有组件。主要必填字段是协议和主机,没有它们,请求将没有要请求的资源。 |
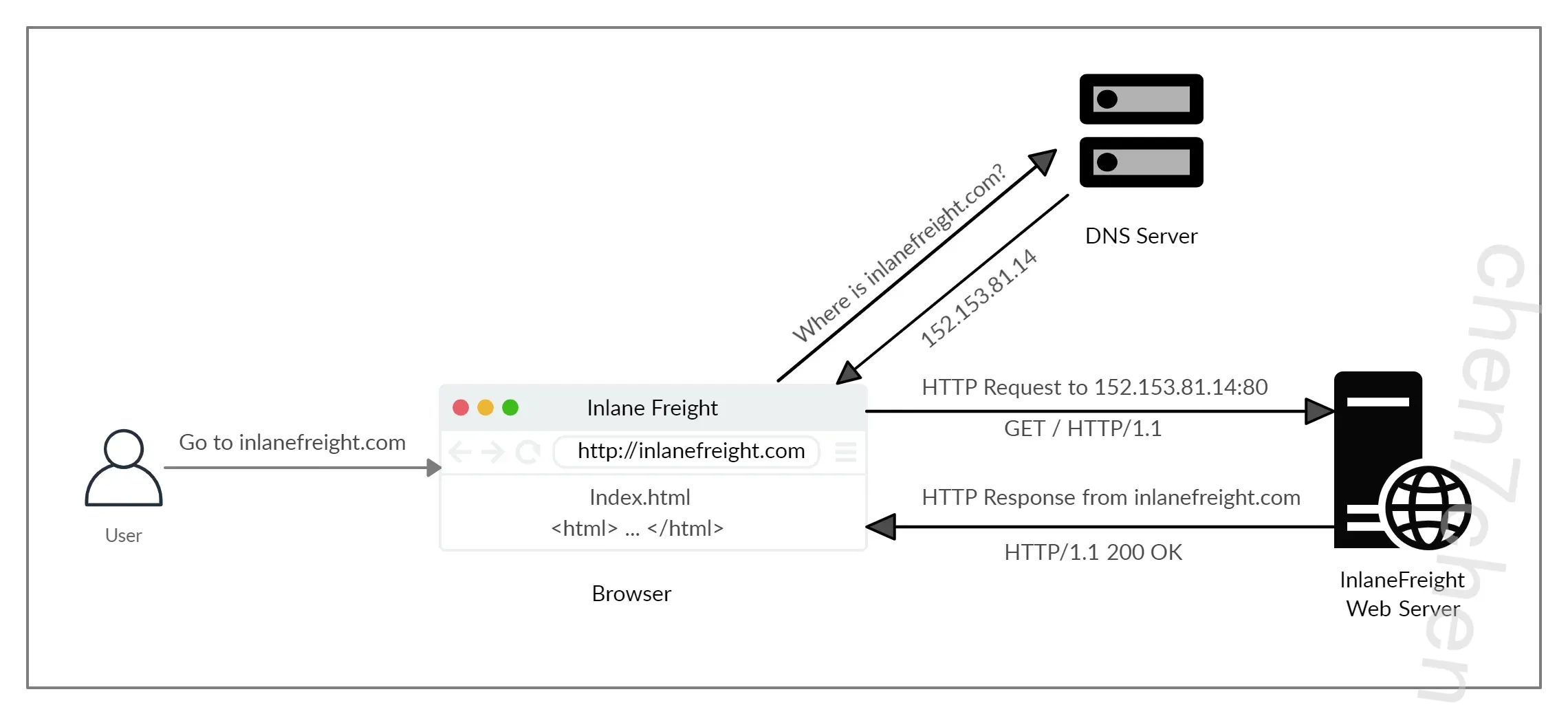
上面的图表以非常高的层次展示了 HTTP 请求的解剖结构。当用户第一次将 URL( inlanefreight.com )输入浏览器时,它会向 DNS(域名系统)服务器发送请求以解析域名并获取其 IP 地址。DNS 服务器查找 inlanefreight.com 的 IP 地址并将其返回。所有域名都需要以这种方式进行解析,因为服务器如果没有 IP 地址就无法通信。
一旦浏览器获取与请求域名关联的 IP 地址,它将向默认 HTTP 端口(例如 80 )发送 GET 请求,请求根 / 路径。然后,Web 服务器接收请求并处理它。默认情况下,服务器配置为在接收到 / 请求时返回索引文件。
在这种情况下, index.html 的内容被读取并由 Web 服务器作为 HTTP 响应返回。响应还包含状态码(例如 200 OK ),该状态码指示请求已成功处理。然后,Web 浏览器渲染 index.html 的内容并将其呈现给用户。
超文本传输安全协议 (HTTPS)
HTTP 的一大显著缺点是所有数据都以明文形式传输。这意味着在源地址和目标地址之间的任何人都可以执行中间人(MiTM)攻击来查看传输的数据。
为了解决这个问题,创建了 HTTPS(HTTP 安全)协议,在该协议中,所有通信都以加密格式传输,因此即使第三方拦截了请求,他们也无法从中提取数据。因此,HTTPS 已成为互联网上网站的主流方案,而 HTTP 正在被逐步淘汰,不久之后大多数网络浏览器将不再允许访问 HTTP 网站。
流程
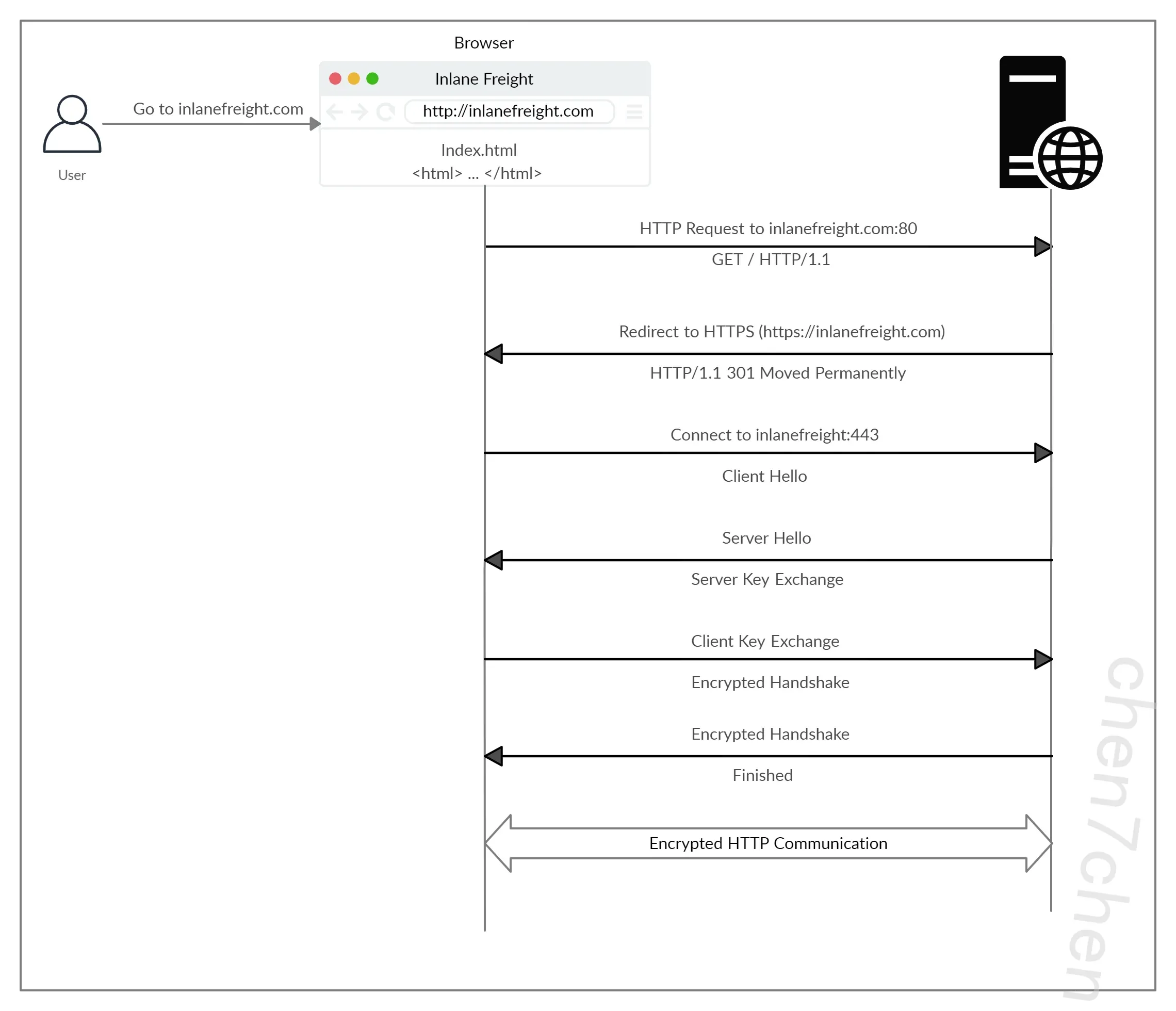
如果我们输入 http:// 而不是 https:// 来访问一个强制使用 HTTPS 的网站,浏览器会尝试解析域名并将用户重定向到托管目标网站的 Web 服务器。首先会向端口 80 发送请求,这是未加密的 HTTP 协议。服务器检测到这一点后,会通过 301 Moved Permanently 响应代码将客户端重定向到安全的 HTTPS 端口 443 。我们将在接下来的部分讨论这个响应代码。
接下来,客户端(网页浏览器)发送一个“客户端问候”数据包,提供有关其自身的信息。之后,服务器回复“服务器问候”,然后进行密钥交换以交换 SSL 证书。客户端验证密钥/证书并发送自己的一个。之后,启动加密握手以确认加密和传输是否正常工作。
一旦握手成功完成,就会继续正常的 HTTP 通信,此后通信将被加密。
注意:根据具体情况,攻击者可能能够执行 HTTP 降级攻击,将 HTTPS 通信降级为 HTTP,使传输的数据以明文形式显示。这是通过设置一个中间人(MITM)代理来完成的,该代理在不让用户知情的情况下将所有流量通过攻击者的主机进行传输。然而,大多数现代浏览器、服务器和 Web 应用程序都保护免受此类攻击。
数据包
HTTP请求和响应
HTTP 通信主要由 HTTP 请求和 HTTP 响应组成。HTTP 请求由客户端(例如 cURL/浏览器)发起,并由服务器(例如 Web 服务器)处理。请求包含我们从服务器所需的所有详细信息,包括资源(例如 URL、路径、参数)、任何请求数据、我们指定的头部或选项,以及本模块中我们将讨论的许多其他选项。
通用头
通用头部在 HTTP 请求和响应中都使用。它们是上下文相关的,用于 describe the message rather than its contents 。
| 头部 | 示例 | 描述 |
|---|---|---|
Date | Date: Wed, 16 Feb 2022 10:38:44 GMT | 包含消息产生的日期和时间。建议将时间转换为标准的 UTC 时区。 |
Connection | Connection: close | 指定当前网络连接在请求完成后是否保持活跃。此头部常用的两个值是 close 和 keep-alive 。来自客户端或服务器的 close 值表示他们希望终止连接,而 keep-alive 头部表示连接应保持打开状态以接收更多数据和输入。 |
实体头
类似于通用头,实体头可以是 common to both the request and response 。这些头用于 describe the content (实体) 通过消息传输。它们通常出现在响应和 POST 或 PUT 请求中。
| Header 头 | Example 示例 | Description 描述 |
|---|---|---|
Content-Type | Content-Type: text/html | 用于描述正在传输的资源类型。值由客户端浏览器自动添加并在服务器响应中返回。 charset 字段表示编码标准,例如 UTF-8。 |
Media-Type | Media-Type: application/pdf | media-type 与 Content-Type 类似,用于描述正在传输的数据。此头部字段在让服务器解释我们的输入时可能起到关键作用。 charset 字段也可能与此头部字段一起使用。 |
Boundary | boundary="b4e4fbd93540" | 当同一消息中包含多个内容时,用作分隔内容的标记。例如,在表单数据中,此边界用作 --b4e4fbd93540 以分隔表单的不同部分。 |
Content-Length | Content-Length: 385 | 包含正在传递的实体的尺寸。此头部字段是必要的,因为服务器使用它从消息正文中读取数据,并由浏览器以及 cURL 等工具自动生成。 |
Content-Encoding | Content-Encoding: gzip | 数据在被传递之前可能经过多次转换。例如,大量数据可以被压缩以减小消息大小。应使用 Content-Encoding 头部字段指定正在使用的编码类型。 |
请求头
让我们从检查以下示例 HTTP 请求开始:
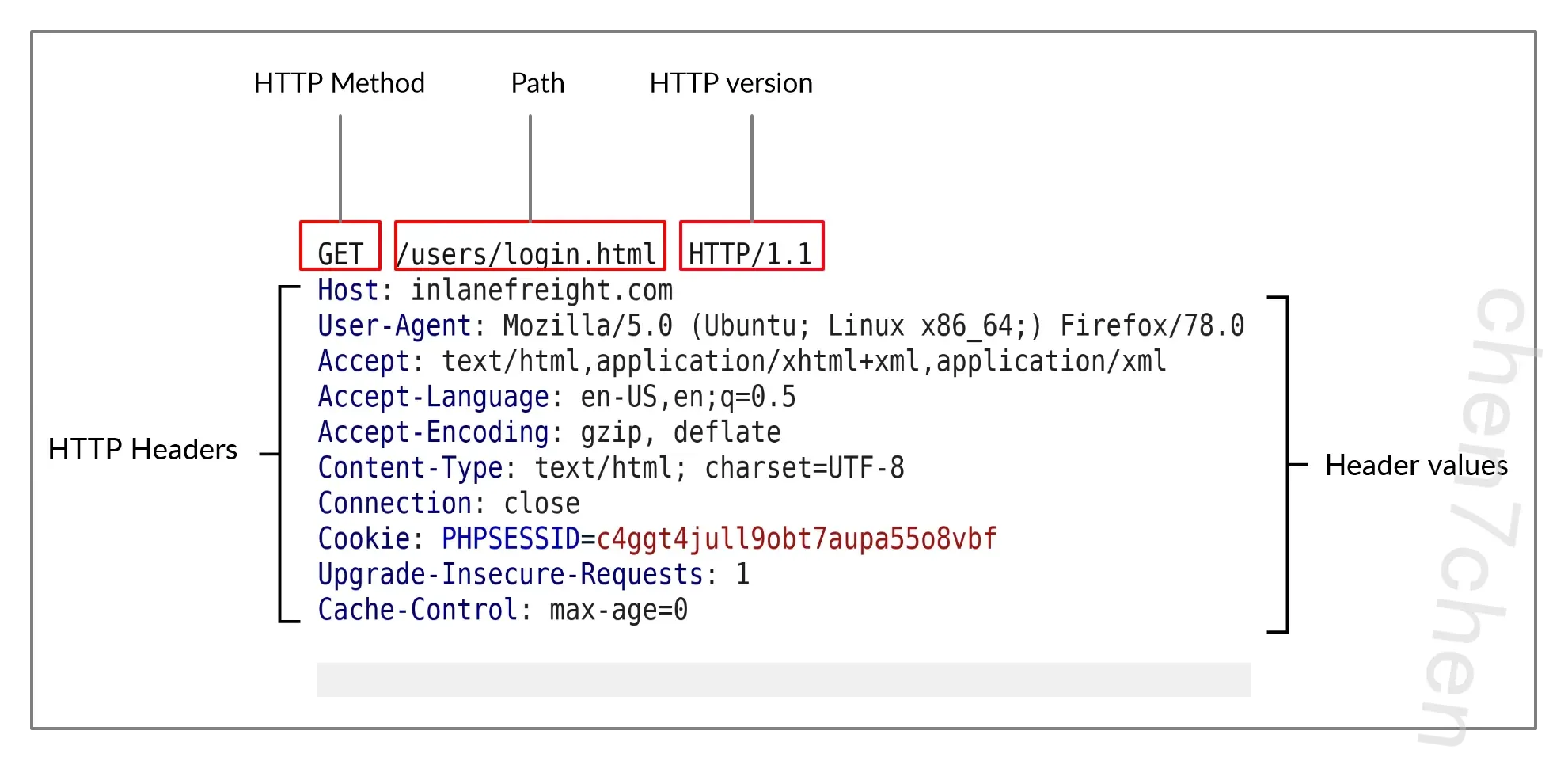
任何 HTTP 请求的第一行包含三个主要字段,由空格分隔:
| 字段 | 示例 | 描述 |
|---|---|---|
Method | GET | 方法或动词,指定要执行的操作类型。 |
Path | /users/login.html | 访问资源的路径。该字段还可以附加查询字符串(例如 ?username=user )。 |
Version | HTTP/1.1 | 第三个也是最后一个字段用于表示 HTTP 版本。 |
接下来的几行包含 HTTP 头部值对,例如 Host 、 User-Agent 、 Cookie 以及许多其他可能的头部。这些头部用于指定请求的各种属性。头部以换行符结束,这对于服务器验证请求是必要的。最后,请求可能以请求体和数据结束。
注意:HTTP 版本 1.X 以明文形式发送请求,并使用换行符来分隔不同的字段和不同的请求。而 HTTP 版本 2.X 则以二进制数据的形式以字典形式发送请求。
客户端在 HTTP 事务中发送请求头。这些头是消息的一部分。
| 头 | 示例 | 描述 |
|---|---|---|
Host | Host: www.inlanefreight.com | 用于指定资源查询的主机。这可以是一个域名或一个 IP 地址。HTTP 服务器可以配置为托管不同的网站,这些网站根据主机名显示。这使得主机头成为重要的枚举目标,因为它可以指示目标服务器上其他主机的存在。 |
User-Agent | User-Agent: curl/7.77.0 | User-Agent 头部用于描述请求资源的客户端。这个头部可以揭示很多关于客户端的信息,例如浏览器、版本和操作系统。 |
Referer | Referer: http://www.inlanefreight.com/ | 表示当前请求来自哪里。例如,从 Google 搜索结果中点击链接会使 https://google.com 成为 Referer。信任这个头部可能很危险,因为它很容易被操纵,导致意想不到的后果。 |
Accept | Accept: */* | Accept 头部描述客户端可以理解哪些媒体类型。它可以包含用逗号分隔的多个媒体类型。 */* 值表示接受所有媒体类型。 |
Cookie | Cookie: PHPSESSID=b4e4fbd93540 | 包含 name=value 格式的 cookie-value 对。Cookie 是存储在客户端和服务器上的数据片段,用作标识符。它们随每个请求传递给服务器,从而维护客户端的访问。Cookie 还可以用于其他目的,例如保存用户偏好或会话跟踪。单个头部中可以有多个用分号分隔的 cookie。 |
Authorization | Authorization: BASIC cGFzc3dvcmQK | 服务器识别客户端的另一种方法。在成功认证后,服务器会返回一个仅属于该客户端的唯一令牌。与 Cookie 不同,令牌仅存储在客户端,并且每次请求时由服务器检索。根据使用的 Web 服务器和应用类型,存在多种认证类型。 |
GET
每当访问任何 URL 时,我们的浏览器默认使用 GET 请求来获取该 URL 上托管的远程资源。一旦浏览器接收到它正在请求的初始页面,它可能会使用各种 HTTP 方法发送其他请求。
POST
每当 Web 应用需要传输文件或将用户参数从 URL 中移除时,它们会使用 POST 请求。
与将用户参数放置在 URL 中的 HTTP GET 不同,HTTP POST 将用户参数放置在 HTTP 请求体中。这有三个主要优势:
- 由于 POST 请求可能会传输大型文件(例如文件上传),服务器将所有上传的文件作为请求 URL 的一部分进行记录将效率不高,这与通过 GET 请求上传文件的情况不同。
- URL 的设计目的是为了共享,这意味着它们需要符合可以转换为字母的字符。POST 请求将数据放置在请求体中,请求体可以接受二进制数据。需要编码的唯一字符是用于分隔参数的那些字符。
- 最大 URL 长度在不同的浏览器(Chrome/Firefox/IE)、Web 服务器(IIS、Apache、nginx)、内容分发网络(Fastly、Cloudfront、Cloudflare)甚至 URL 缩短服务(bit.ly、amzn.to)之间存在差异。一般来说,URL 的长度应保持在 2,000 个字符以下,因此它们无法处理大量数据。
Content-Type
因为 GET 请求通常不包含请求体(数据都在 URL 中),所以 Content-Type 主要在 POST、PUT 等包含请求体的操作中发挥重要作用:
application/x-www-form-urlencoded- 说明:这是 Web 表单(
<form>)默认的提交格式。 - 特点:数据会被编码成以
&分隔的键值对(例如:user=admin&pass=123456),并且 URL 编码其中的非字母数字字符。
- 说明:这是 Web 表单(
multipart/form-data- 说明:通常用于表单文件上传。
- 特点:当上传大型文件或二进制数据时,这种方式效率最高。它会在请求头中生成一个
boundary(随机边界字符串),用来在请求体中分割不同的数据段(如文本字段和文件流)。
application/json- 说明:告诉服务器发送的是 JSON 格式的数据。
- 特点:这是目前现代 Web 应用(前后端分离)、RESTful API 和移动端最常用的数据交互格式(例如:
{"user":"admin", "pass":"123456"})。
text/xml或application/xml- 说明:用于发送 XML 数据,常见于较老的 SOAP Web 服务或微信支付等特定 API。
响应头
当服务器处理我们的请求后,它会发送响应。以下是一个 HTTP 响应的示例
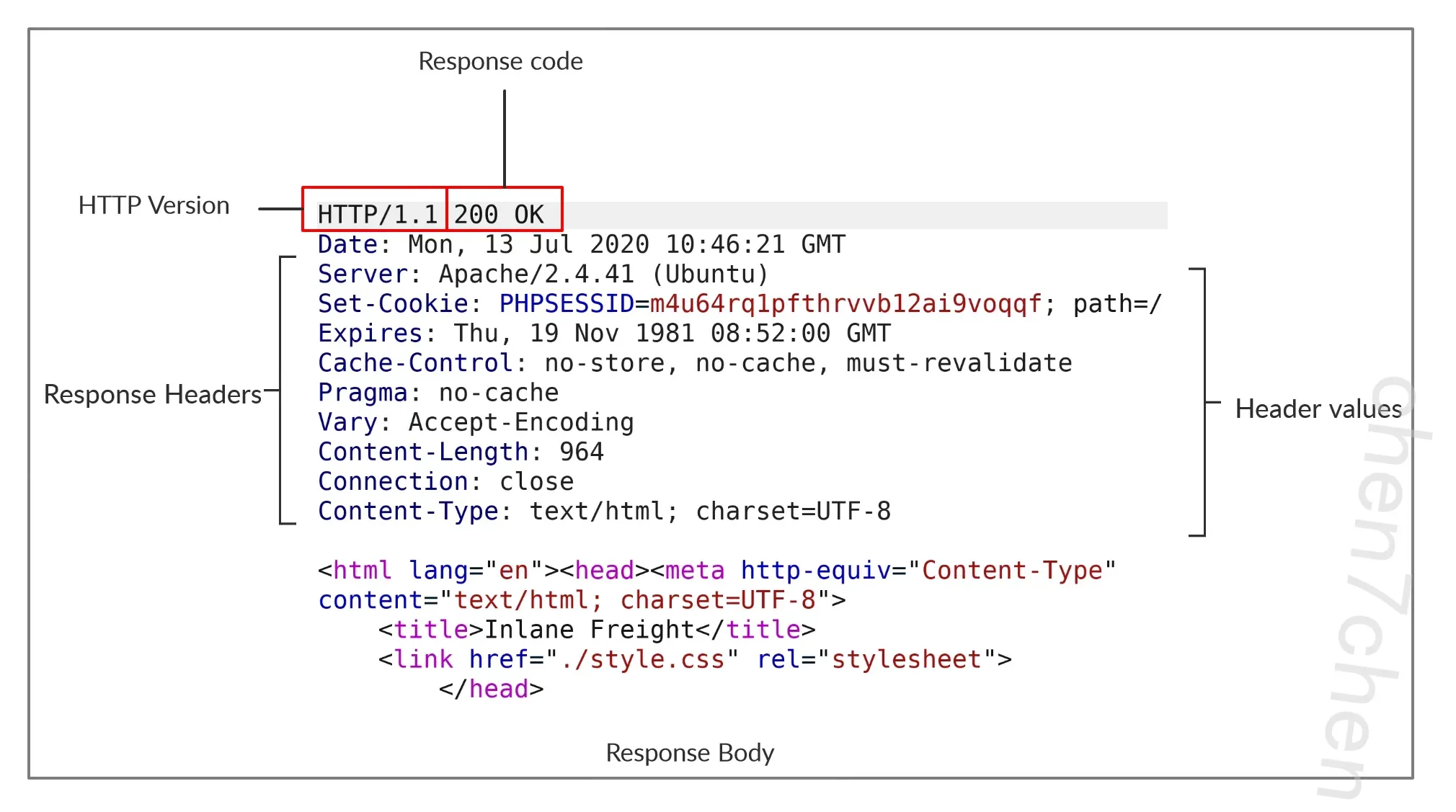 HTTP 响应的第一行包含两个由空格分隔的字段。第一个字段是
HTTP 响应的第一行包含两个由空格分隔的字段。第一个字段是 HTTP version (例如 HTTP/1.1 ),第二个字段表示 HTTP response code (例如 200 OK )。
响应码用于确定请求的状态,将在后续部分讨论。第一行之后,响应列出了其头部信息,类似于 HTTP 请求。
最后,响应可能以响应正文结束,响应正文在头部之后通过新行分隔。响应正文通常定义为 HTML 代码。但是,它也可以响应其他类型的代码,例如 JSON ,网站资源,如图像、样式表或脚本,甚至可以是托管在 Web 服务器上的文档,如 PDF 文档。
HTTP 基本认证
当我们访问本节末尾找到的练习时,它会提示我们输入用户名和密码。与通常使用 HTTP 参数来验证用户凭证的登录表单(例如 POST 请求)不同,这种类型的认证使用 basic HTTP authentication ,它由 Web 服务器直接处理,以保护特定的页面/目录,而无需直接与 Web 应用程序交互
要访问该页面,我们必须输入一对有效的凭证
用curl是这样发送数据包的
curl http://admin:admin@<SERVER_IP>:<PORT>/
<!DOCTYPE html>
<html lang="en">
<head>
我们还可以尝试在浏览器中访问相同的 URL,并且应该也能通过身份验证。
请求方法
HTTP 支持多种访问资源的方法。在 HTTP 协议中,几种请求方法允许浏览器向服务器发送信息、表单或文件。这些方法用于告诉服务器如何处理我们发送的请求以及如何回复。
| Method 方法 | Description 描述 |
|---|---|
GET | 请求特定资源。可以通过 URL 中的查询字符串将额外数据传递给服务器(例如 ?param=value )。 |
POST | 将数据发送到服务器。它可以处理多种类型的输入,如文本、PDF 文件和其他二进制数据。这些数据附加在位于请求头之后的请求正文中。POST 方法通常用于发送信息(例如表单/登录)或上传数据到网站,如图像或文档。 |
HEAD | 请求在向服务器发起 GET 请求时返回的头部信息。它不会返回请求体,通常用于在下载资源之前检查响应长度。 |
PUT | 在服务器上创建新资源。如果没有适当的控制就允许此方法,可能会导致上传恶意资源。 |
DELETE | 删除 Web 服务器上的现有资源。如果安全性配置不当,可能会通过删除 Web 服务器上的关键文件来导致拒绝服务 (DoS)。 |
OPTIONS | 返回有关服务器的信息,例如它接受的请求方法。 |
PATCH | 应用于指定位置的资源的部分修改。 |
注意:大多数现代 Web 应用主要依赖于 GET 和 POST 方法。然而,任何使用 REST API 的 Web 应用也依赖于 PUT 和 DELETE ,分别用于在 API 端点更新和删除数据。有关更多详细信息,请参阅 Web 应用入门模块。 |
状态码
HTTP 状态码用于告知客户端其请求的状态。HTTP 服务器可以返回五种类别的状态码:
| 类别 | 描述 |
|---|---|
1xx | 提供信息且不影响请求的处理。 |
2xx | 当请求成功时返回。 |
3xx | 当服务器重定向客户端时返回。 |
4xx | 表示不适当的请求 from the client 。例如,请求一个不存在的资源或请求一个错误的格式。 |
5xx | 当 with the HTTP server 本身存在问题时返回。 |
认证后的 Cookie
如果我们成功认证,应该会收到一个 Cookie,以便我们的浏览器可以持久化我们的认证状态,这样我们就不需要每次访问页面时都登录。我们可以使用 -v 或 -i 标志查看响应,其中应该包含 Set-Cookie 头部,包含我们的认证 Cookie
抓包
概念
抓包(packet capture)就是将网络传输发送与接收的数据包进行截获、重发、编辑、转存等操作,也用来检查网络安全。抓包也经常被用来进行数据截取等。
原理
数据在网络上是以很小的称为帧(Frame)的单位传输的,帧由几部分组成,不同的部分执行不同的功能。帧通过特定的称为网络驱动程序的软件进行成型,然后通过网卡发送到网线上,通过网线到达它们的目的机器,在目的机器的一端执行相反的过程。接收端机器的以太网卡捕获到这些帧,并告诉操作系统帧已到达,然后对其进行存储。就是在这个传输和接收的过程中,嗅探器会带来安全方面的问题。
每一个在局域网(LAN)上的工作站都有其硬件地址,这些地址唯一地表示了网络上的机器(这一点与Internet地址系统比较相似)。当用户发送一个数据包时,如果为广播包,则可达到局域网中的所有机器,如果为单播包,则只能到达处于同一碰撞域中的机器。
在一般情况下,网络上所有的机器都可以“听”到通过的流量,但对不属于自己的数据包则不予响应(换句话说,工作站A不会捕获属于工作站B的数据,而是简单地忽略这些数据)。如果某个工作站的网络接口处于混杂模式,那么它就可以捕获网络上所有的数据包和帧。
分类
(一)web应用站点-浏览器直接查看元素网络监听
(二)APP&小程序&PC抓包-Charles&Fiddler&Burpsuite
(三)程序进程&网络接口-wireshark&科来网络分析系统
(四)通讯类应用封包发送接收-WPE四件套封包&科来网络分析系统
API
许多 API 用于与数据库交互,以便我们能够在 API 查询中指定请求的表和请求的行,然后使用 HTTP 方法执行所需的操作。
CRUD
我们可以通过此类 API 轻松指定要执行操作的表和行。然后我们可以利用不同的 HTTP 方法对该行执行不同的操作。通常,API 对请求的数据库实体执行 4 种主要操作:
| Operation 操作 | HTTP Method HTTP 方法 | Description 描述 |
|---|---|---|
Create | POST | 将指定数据添加到数据库表 |
Read | GET | 从数据库表中读取指定实体 |
Update | PUT | 更新指定数据库表的数据 |
Delete | DELETE | 从数据库表中删除指定的行 |
这四种操作主要与常见的 CRUD API 相关,但相同的原则也用于 REST API 和其他几种类型的 API。当然,并非所有 API 都以相同的方式工作,用户访问控制将限制我们可以执行的操作和可以看到的结果。Web 应用程序简介模块进一步解释了这些概念,因此您可以参考它以获取有关 API 及其用法的更多详细信息。
Read 读取
在与 API 交互时,我们首先会进行读取数据。如前所述,我们可以在 API 后面直接指定表名(例如 /city ),然后指定我们的搜索词(例如 /london ),如下所示:
MichelleCarter@htb[/htb]$ curl http://<SERVER_IP>:<PORT>/api.php/city/london
[{"city_name":"London","country_name":"(UK)"}]
我们看到结果以 JSON 字符串的形式发送。为了使其正确地格式化为 JSON 格式,我们可以将输出通过 jq 工具,它将正确地格式化它。我们还将使用 -s 静默任何不必要 cURL 输出,如下所示:
MichelleCarter@htb[/htb]$ curl -s http://<SERVER_IP>:<PORT>/api.php/city/london | jq
[
{
"city_name": "London",
"country_name": "(UK)"
}
]
如我们所见,我们得到了一个格式良好的输出。我们还可以提供一个搜索词来获取所有匹配的结果:
MichelleCarter@htb[/htb]$ curl -s http://<SERVER_IP>:<PORT>/api.php/city/le | jq
[
{
"city_name": "Leeds",
"country_name": "(UK)"
},
{
"city_name": "Dudley",
"country_name": "(UK)"
},
{
"city_name": "Leicester",
"country_name": "(UK)"
},
...SNIP...
]
我们可以传递一个空字符串来检索表格中的所有条目:
MichelleCarter@htb[/htb]$ curl -s http://<SERVER_IP>:<PORT>/api.php/city/ | jq
[
{
"city_name": "London",
"country_name": "(UK)"
},
{
"city_name": "Birmingham",
"country_name": "(UK)"
},
{
"city_name": "Leeds",
"country_name": "(UK)"
},
...SNIP...
]
Create 创建
要添加新条目,我们可以使用 HTTP POST 请求,这与我们之前执行的操作非常相似。我们只需 POST 我们的 JSON 数据,它就会被添加到表格中。由于这个 API 使用 JSON 数据,我们也将设置 Content-Type 头部为 JSON,如下所示:
MichelleCarter@htb[/htb]$ curl -X POST http://<SERVER_IP>:<PORT>/api.php/city/ -d '{"city_name":"HTB_City", "country_name":"HTB"}' -H 'Content-Type: application/json'
现在,我们可以读取我们添加的城市的内容( HTB_City ),看看是否成功添加:
MichelleCarter@htb[/htb]$ curl -s http://<SERVER_IP>:<PORT>/api.php/city/HTB_City | jq
[
{
"city_name": "HTB_City",
"country_name": "HTB"
}
]
Update更新
现在我们已经知道如何通过 API 读取和写入条目,让我们开始讨论另外两种我们之前没有使用过的 HTTP 方法: PUT 和 DELETE 。正如本节开头所述, PUT 用于更新 API 条目并修改其详细信息,而 DELETE 用于删除特定实体。
注意:HTTP PATCH 方法也可以用来更新 API 条目,而不是 PUT 。准确地说, PATCH 用于部分更新条目(仅修改其部分数据,例如仅修改 city_name),而 PUT 用于更新整个条目。我们也可以使用 HTTP OPTIONS 方法来查看服务器接受哪一种,然后相应地使用适当的方法。在本节中,我们将重点关注 PUT 方法,尽管它们的用法非常相似。
使用 PUT 在此情况下与 POST 非常相似,唯一的区别在于我们必须在 URL 中指定要编辑实体的名称,否则 API 将不知道要编辑哪个实体。因此,我们只需在 URL 中指定 city 名称,将请求方法更改为 PUT ,并提供类似于 POST 的 JSON 数据,如下所示:
MichelleCarter@htb[/htb]$ curl -X PUT http://<SERVER_IP>:<PORT>/api.php/city/london -d '{"city_name":"New_HTB_City", "country_name":"HTB"}' -H 'Content-Type: application/json'
DELETE 删除
最后,让我们尝试删除一个节点
MichelleCarter@htb[/htb]$ curl -X DELETE http://<SERVER_IP>:<PORT>/api.php/city/New_HTB_City
Web
与原生操作系统(native OS)应用程序不同,Web 应用程序是平台无关的,可以在任何操作系统上的浏览器中运行。这些 Web 应用程序无需安装在用户的系统上,因为它们的功能是在远程服务器上远程执行的,因此不会占用最终用户硬盘的任何空间。
Web 应用程序相对于原生操作系统应用程序的另一个优势是版本统一性。所有访问 Web 应用程序的用户都使用相同的版本和相同的 Web 应用程序,该应用程序可以不断更新和修改,而无需向每个用户推送更新。Web 应用程序可以在一个位置(Web 服务器)进行更新,而无需为每个平台开发不同的版本,这大大降低了维护和支持成本,无需单独向所有用户传达更改。
另一方面,原生操作系统应用程序相对于 Web 应用程序具有一定的优势,主要体现在它们的运行速度以及能够利用原生操作系统库和本地硬件。由于原生应用程序是构建来利用原生操作系统库的,因此它们加载和交互的速度要快得多。此外,原生应用程序通常比 Web 应用程序功能更强大,因为它们与操作系统有更深的集成,并且不受限于浏览器的功能。
然而,最近混合式和渐进式网络应用程序正变得越来越普遍。它们利用现代框架,通过原生操作系统功能和资源来运行网络应用程序,使其比常规网络应用程序更快、功能更强。
安全风险
网络应用攻击普遍存在,对大多数拥有网络存在的组织都构成了挑战,无论其规模大小。毕竟,它们通常可以通过任何拥有互联网连接和网页浏览器的任何人从任何国家访问,并且通常提供广阔的攻击面。有许多用于扫描和攻击网络应用的自动化工具,如果落入错误之手,可能会造成重大损害。随着网络应用变得越来越复杂和先进,其设计中包含关键漏洞的可能性也随之增加。
一次成功的网络应用攻击可能导致重大损失和巨大的业务中断。由于网络应用通常运行在可能托管其他敏感信息的服务器上,并且经常链接到包含敏感用户或企业数据的数据库,如果网站成功被攻击,所有这些数据都可能被泄露。这就是为什么任何利用网络应用的企业都必须对这些应用进行漏洞测试,并及时修复漏洞,同时在测试中确保补丁能够修复缺陷,而不会无意中引入新的缺陷。
网络应用渗透测试是一项日益重要的技能。任何希望保护其面向互联网(和内部)的网络应用的组织都应进行频繁的网络应用测试,并在每个开发生命周期阶段实施安全的编码实践。为了正确地进行网络应用渗透测试,我们需要了解它们的工作原理、开发方式,以及根据所使用的技术,应用每一层和组件中存在的风险类型。
我们将始终遇到设计、配置各不相同的各种网络应用。目前最常用和广泛使用的网络应用测试方法之一是 OWASP Web Security Testing Guide。
最常见的流程之一是首先审查 Web 应用的前端组件,例如 HTML 、 CSS 和 JavaScript (也称为前端三件套),并尝试寻找诸如敏感数据泄露和跨站脚本(XSS)等漏洞。一旦所有前端组件都经过彻底测试,我们通常会审查 Web 应用的核心功能以及浏览器与 Web 服务器的交互,以枚举 Web 服务器使用的技术并寻找可利用的缺陷。我们通常会从未经身份验证和经过身份验证(如果应用程序具有登录功能)的角度评估 Web 应用,以最大化覆盖范围并审查所有可能的攻击场景。
攻击
在这个时代,几乎每家公司,无论大小,在其外部边界内都至少有一个或多个网络应用程序。这些应用程序可以是简单的静态网站,由内容管理系统(CMS)如 WordPress 驱动的博客,到具有注册/登录功能的复杂应用程序,支持从普通用户到超级管理员的各种用户角色。如今,找到一个直接可通过已知公共漏洞(如易受攻击的服务或 Windows 远程代码执行(RCE)漏洞)进行外部主机利用的情况并不常见,尽管这种情况确实会发生。网络应用程序提供了一个广阔的攻击面,并且由于它们的动态特性,它们会不断变化(并且容易被忽视!)。一个相对简单的代码更改可能会引入灾难性的漏洞或一系列可以串联起来以获取敏感数据或在网络服务器或其他环境中主机(如数据库服务器)上执行远程代码的漏洞。
发现可直接导致代码执行的漏洞并不少见,例如允许上传恶意代码的文件上传表单或可被利用以获取远程代码执行的文件包含漏洞。SQL 注入是一种仍然在各种类型 Web 应用程序中相当普遍的著名漏洞。这种漏洞源于对用户提供的输入处理不当。它可能导致访问敏感数据、在数据库服务器上读取/写入文件,甚至远程代码执行。
我们经常在使用活动目录进行身份验证的 Web 应用中发现 SQL 注入漏洞。虽然我们通常无法利用这一点来提取密码(因为活动目录管理密码),但我们通常可以拉取大部分或所有活动目录用户电子邮件地址,这些地址通常与他们的用户名相同。然后可以使用这些数据对使用活动目录进行身份验证的 Web 端口(如 VPN 或 Microsoft Outlook Web Access/Microsoft 365)执行密码喷洒攻击。一次成功的密码喷洒攻击通常可以访问敏感数据(如电子邮件),甚至可以直接进入企业网络环境。